
Using SQLAlchemy and Flask to build a simple, data-driven web app
If you haven’t come across Flask yet, it’s a great Python web development framework for building simple static sites, all the way up to large enterprise web apps. However, it’s up to you to figure out how to display frontend content and how to connect a database. If you’re familiar with the MVC architecture, Flask provides the C (controller), and you provide the rest. For a beginner, it might be difficult to get started with such a bare-bones framework, especially if you don’t have much experience with databases. That’s why I’ve put together this handy tutorial, based on a talk I gave on SQLAlchemy.
I’ve explained a little bit about what Flask does (and doesn’t do out of the box), but you might be wondering what SQLAlchemy is. SQLAlchemy is a toolkit that simplifies working with databases by creating and optimizing the SQL statements for you. This is accomplished by using the Object Relational Mapper (ORM), which provides a link between Python classes and database tables. Thankfully, the details of database specific SQL and connection persistence are hidden away, but still allow full access to table schemas and powerful querying.
That sounds good, but what are the advantages of SQLAlchemy? First and foremost, SQLAlchemy is database agnostic, meaning it can be used with MySQL, Postgres, SQLite, Microsoft SQL Server, and Oracle to name a few. Also, SQL data types are automatically converted to their closest equivalent Python data type. This makes working with dates and times easier because there’s no custom conversion code to convert from a string to a Datetime object. Finally, SQLAlchemy’s ORM allows you to work with tables, queries, and results as Python objects so it isn’t necessary to write a single line of SQL.
All of these features make SQLAlchemy great for building relational database-driven Python apps, ETL and analytics jobs, and even Flask web apps!
For this tutorial, I’ve built a simple, static website that lists various live music venues in Austin Texas. A small database will store the name of the venue, address, description, url to an image of the venue, and a flag for indicating whether the venue is closed. It would also be nice to have user reviews and ratings for each venue. Here’s an image of what the venue list looks like:

The site is structured so that there’s a main page that lists each venue, and a reviews page that lists the reviews and ratings for each venue. There’s a button titled “Reviews” for each venue that will open the reviews page and list the user reviews for that venue.
This tutorial will explain how to:
- Understand the high level architecture.
- Develop the database schema.
- Install and setup the database via Docker.
- Setup the conda environment and run Flask.
- Import data into the database.
- Interpret and understand the Python code.
Pre-requisites
- A basic understanding of coding and Python.
- A basic understanding of full stack development.
- A moderate understanding of Bash and the command line.
The Architecture
Before getting into the architecture and it’s interactions, let’s first consider the tech stack:
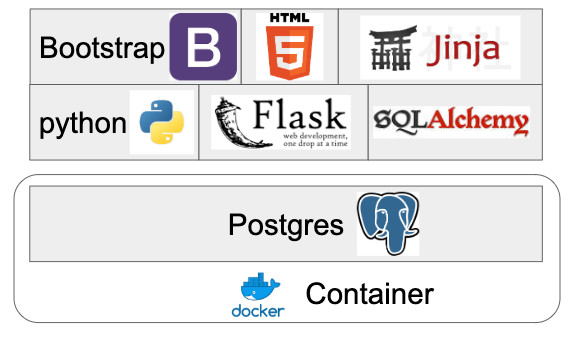
The database is Postgres running inside a Docker container. The site backend is written in Python with Flask serving up content and SQLAlchemy providing the connection between Flask and the database. The pages themselves are static Bootstrap templates written in HTML with Jinja providing content that’s loaded from the database.
The Austin Music Venues site is fairly simple and is composed of three main pieces:
- The Database — Stores all the site content
- The Webserver — Runs the Python code
- The Client — Displays content returned from the webserver.
Simply put, our browser makes a request from the webserver for a page. The webserver then runs the necessary Python code and interacts with the database. The database sends back any requested data, and that data is then worked into an HTML template that is sent to the client.
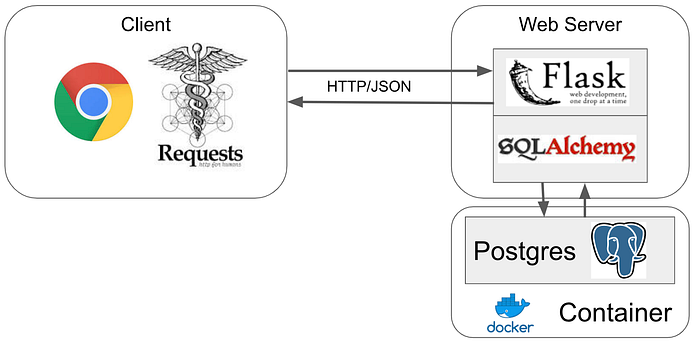
In MVC architecture terms, the M is the Postgres database, the C is the webserver, and the V is the rendered HTML.
All the data for the site is stored in the database and served to the web browser by Flask. If we’re going to store and serve the data in an efficient manner, how should it be stored?
The Database Schema
Since the site is for music venues, there should certainly be a database table of venues. Each venue has a name, a description, an image, and an address. Music venues can also close over time, so there should be a boolean field to represent the closed state. Since an address has various parts such as a street, zip code, city, and state, addresses should be in their own table. There might be the temptation to combine addresses into the music venue table. However, consider the situation where a music venue closes and a new one takes its place at the same address. Or, perhaps the venue that closed opens at a new address. To prevent duplication in the table, it’s a better idea to put addresses into their own table and have the venue table refer to specific addresses in the address table.
In the case of ratings, a user could provide a review and a whole number score on a scale from 1 to 5. Since each venue could have multiple ratings from users, these ratings should be stored in their own table and refer to the venue they are a rating for. This gives us the schema defined below:

Getting Started
Before working with any code, three things need to be installed:
- Git
- Anaconda
- Docker
Git is needed to clone and pull the Github repository with the tutorial code. If the system you are working on doesn’t have Git installed, you can follow the instructions here. If you are on Windows, it’s easier to install git from gitforwindows.org.
Anaconda provides the Python, Flask, and SQLAlchemy environment needed to run the webserver and backend code. If you need to install Anaconda, the simplified Minconda is a good alternative and can be installed here.
Finally, Docker is a great way to install and try out databases, languages, frameworks, and tools. This makes getting the Postgres database up and running a snap. Docker can be installed on modern versions of most OSs here.
Cloning the Repo
Once everything is installed, the Austin Music Venues repo can be cloned from https://github.com/cmmorrow/austin_music_venues. In a new terminal or Git Bash session, the repo can be cloned and downloaded with the following command:
git clone https://github.com/cmmorrow/austin_music_venues.gitThe directory structure should like like this:
austin_music_venues
├── app
│ ├── static
│ │ ├── ratings.json
│ │ └── venues.json
│ ├── templates
│ │ ├── main.html
│ │ └── reviews.html
│ ├── __init__.py
│ ├── app.py
│ └── load_data.py
├── postgres
│ ├── amvdb.sql
│ └── Dockerfile
├── notebooks
│ ├── Demo.ipynb
│ └── Demo Final.ipynb
├── environment.yml
└── README.mdOnce you have the repository, it’s time to setup the database.
Setting Up the Database
Once the repo is on the local system and Docker is running, the database can be started. In the same terminal window, move into the austin_music_venues/postgres directory, build the database image, and launch the container with the following commands:
cd austin_music_venues/postgres
docker build -t amvdb_postgres .
docker run -d -p 5433:5432 -e POSTGRES_DB=amvdb --name amvdb amvdb_postgresThere should now be a Postgres database called amvdb running on the local system on port 5433. How did this work? The docker build command ran the Dockerfile in austin_music_venues/postgres which downloads the newest postgres image from Docker Hub and copies the SQL file in the austin_music_venues/postgres directory into the new image. When the container is started with the docker run command, a new default database called amvdb is created and the SQL file is executed, creating the user “demo”, the venue, address, and rating tables, and sets the owner of all three tables to demo. The user demo doesn’t have a password, so logging into the server from the command line or a management tool like pgAdmin should be easy.
Configuring and Starting Flask
The database should be up and running, but the tables are empty. This can be verified by starting the Flask development webserver and visiting the site in a web browser. To do that, Flask needs to set two environment variables before running, which can be done with the following commands:
export FLASK_APP=app
export FLASK_ENV=developmentThe FLASK_APP environment variable tells Flask where the entry point for the backend Python code can be found and FLASK_ENV tells Flask to start up in development mode. Development mode is handy because the server is restarted automatically every-time there is a saved change to the code. Before starting the webserver, it’s important to activate the conda environment. This can be done with:
cd ..
conda env create -f environment.ymlThis command will install all the necessary Python packages and isolate them in the austin_music_venues conda environment so that they don’t interfere with any existing Python packages or versions that might already be installed on the local system. The conda environment can then be activated with:
conda activate austin_music_venuesThe prompt on the command line should now reflect the change to the new environment. Finally, it’s time to run Flask:
cd app
flask runThe webserver will start and the site will be hosted at http://localhost:5000. The change to the app directory was needed so that the FLASK_APP environment variable is pointing to the correct directory. In a new browser tab or window, navigate to to http://localhost:5000. If everything went right, you should see just a title at the top of the page that says “Austin Music Venues.” Nothing else appears because there’s no data in the database, but confirms that Flask is working correctly.
Loading the Sample Data Into the Database
The repo has two JSON files, venues.json and ratings.json in the austin_music_venues/app/static directory. The sample data in both of these files can be loaded into the database with the Python script load_data.py in the austin_music_venues/app directory. Let’s take a look at what the script does:
This script reads the contents of the venues.json and ratings.json files then converts the text as JSON to a native Python data structure. First, each venue in the list of venues is inserted into the data base by calling the /add/venue REST API endpoint. Next, the same process is repeated for each review by calling the /add/rating endpoint.
The script can be run with the following command in a new terminal or Git Bash window by changing <path to repo> with the correct corresponding path:
cd <path to repo>/austin_music_venues/app
python ./load_data.pyNow, refresh the page at http://localhost:5000 and the content should now be visible! To stop the Flask webserver at anytime, press CTRL(CMD)+c in the terminal window where the Flask is running.
The Code
Now that the site is working, let’s dig into the code that makes it work.
Instantiating Flask and SQLAlchemy
Before any Python code can talk to the webserver and the database, we have to create a new Flask object that will serve as our application and create a new SQLAlchemy object to define the ORM objects and access the ORM Session.
The above code imports Flask and SQLAlchemy, then creates a new Flask object called app. With app, SQLAlchemy can be configured to connect to the Postgres database running in the Docker container. The connection string URI on line 8 is passed through to the Python DBAPI and says “connect to a postgresql database called amvdb using the psycopg2 driver on the host localhost and port 5433 as the user demo with password demo.”
Security Note: Since this is a public username and password, do not store any data in this database other than the data supplied with the tutorial unless the credentials are changed.
The last configuration to app turns on the SQLAlchemy echo feature which will print all the SQL code rendered by SQLAlchemy. This is a handy feature when debugging so that the programmer can see exactly what commands SQLAlchemy is issuing to the database. Finally, a new SQLAlchemy object is created called db that wraps the Flask object app and performs a lot of boilerplate setup for us.
The ORM Classes
To create a mapping between the address, venue, and rating tables in the database and Python, Mapper classes are created for each table and extend the Model class. For example, the Address class that maps to the address table looks like:
Each class attribute represents a column in the address table and is instantiated as the matching type in the address table. The id attribute is marked as the primary key of the table. The same process is repeated for the venue table:
Notice that address_id is designated as a foreign key that relates to the id column in the address table. This establishes a relationship between the venue and address tables and also constrains all possible values in address_id to values only found in the address id column.
Before moving on to the rest of the code, let’s take a minute to discuss the ORM Session.
The ORM Session
The ORM operates with a Session object that maintains the connection to the database and tracks changes to SQLAlchemy objects associated with the Session. This simplifies the process of issuing commands and managing connections by eliminating a lot of boilerplate code. It also allows SQLAlchemy to virtually track changes to all the associated objects before issuing the commands to the database.
You can think of the Session as the go-between Python and the database. A Session object has query(), add(), delete(), and commit() methods that are used to issue each command to the database. In the case of calling the query() method, an object of Venue, Address, or Rating is returned if querying just one of the corresponding tables — otherwise a ResultSet object is returned if querying only specific columns or multiple tables. In the case of adding or deleting a record from a database table with add() or delete(), an object of Venue, Address, or Rating is passed as an argument to the method used. The ORM Session tracks the state of all pending add and delete requests, as well as changes to an instantiated object until the requests are committed to the database with commit(). Once commit() is called, the equivalent SQL commands are issued, and the Session state is cleared of all pending requests.
To clear up some terminology, a Mapper class in Python represents a database table, whereas an instantiated object of a Mapper class represents a row in a database table.
Mapper Class → Table
Mapper Object → Row
Adding Ratings and Venues
Running the load_data.py script called both the /add/venue and /add/rating endpoints. Let’s first look at the code behind the /add/rating endpoint.
The code above starts out by calling the app.route() function decorator which binds the add_rating() Python function to the /add/rating endpoint and accepts HTTP POST requests. The variable payload contains the JSON data sent from the client. The object Rating is then parsed from the JSON data and used to construct a new Rating Mapper object. The newly created Rating Mapper object is then added to the ORM Session and committed to the rating table. Whew! That’s a one-way trip from the client, through the webserver, to the database.
The code for the /add/venue does something very similar, but is a bit more complex because the JSON payload includes the venue as well as the address.
In the code above, the variable payload represents the JSON data from the client, just like add_rating(). However, the difference this time is that the JSON data contains objects for both Venue and Address. Since an address can have multiple venues, we first have to query the database to see if an address to be inserted is already in the address table. If so, we use the resulting Address Mapper object, and if not, create a new Address Mapper object from the JSON data. This Address Mapper object is then associated with a new Venue Mapper object. By creating this association, the ORM Session will know to create a relationship between the new venue record and address record, inserting the address record in the address table if it didn’t already exists.
Displaying the Main Page
When we visit the page at http://localhost:5000, we’re making a call to the root endpoint. The function main() is associated with the root endpoint and renders the list of music venues.
There’s three things going on in the main() function. First, the host URL is set to the variable host, which in this case is “/”. Second, the Venue.get_venues() class method is called which creates a list of ResultSet objects for displaying venue info. More on this in a bit. Lastly, the host URL and list of venue info is passed as the host and venues arguments to the render_template() function. The render_template() function takes the filename of an HTML file in the static directory, any optionally named keyword arguments (in this case venues and host), and returns a string of the HTML template along with generated dynamic content. Dynamic content rendering is handled by Jinja and uses it’s own Python-like syntax. Take a look at the HTML snippet below:
Each ResultSet object in the list venues is turned into a “row” in the HTML where the object attributes are referenced by name using the dot notation. For example, venue.name provides the name of the corresponding venue in the ResultSet object.
A row in the HTML is created for each venue, but how is the venue information pulled from the database? This is handled by the Venue.get_venues() class method. The code for the class method is shown below:
The class method performs a relatively complex query that extracts information for each venue from the venue, address, and rating tables. It would be too much information to display each rating score for each venue on one page, so the average score for each value is calculated instead. A default limit of 25 venues is imposed on the query, and the resulting list of objects is returned.
Displaying the Ratings Page
Clicking the “Reviews” button for a venue will take the user to a page with all the reviews and scores in the database for that venue. When the “Reviews” button is clicked, the /ratings/ endpoint for the corresponding venue is called by venue_id, or the value of the id field for a particular venue.
In the code above, the endpoint indicates it’s “/ratings/<venue_id>”. The <venue_id> is a variable that Flask will interpret as the argument venue_id. You might recall that a link to this endpoint is rendered by the main.html template. Similar to the function main(), render_template() is called, this time using the reviews.html template. There are two keyword arguments passed to the template, ratings and venue.
The value of ratings is set by calling the Rating.get_ratings() class method which runs a simple query to find all records in the rating table that match venue_id. This could be a list of zero, one, or several Rating objects, depending on how many reviews there are for a certain venue. The value of venue should be the name of a music venue. If there are no ratings for the venue, then a query is run to get the name of the venue with matching venue_id. Otherwise, the venue name is extracted from the first Rating object in ratings. How does that happen? The rating table doesn’t store venue names. The answer is it uses a pair of SQLAlchemy features called relationships and back references.
Relationships and Back References
Relationships are used in SQLAlchemy when defining links between tables. For example, let’s examine the relationship between venues and addresses. Each venue has an address, and this is implemented by defining the address_id field as a foreign key in the venue table, and also by declaring a relationship called address. When address is accessed on a Venue object, the corresponding Address object is returned. The address relationship also has another property called a back reference.
The back reference is a name that can be used to follow a relationship in the opposite direction. In this case, a back reference called venues is used on an Address object to refer back to corresponding Venue objects. To summarize, a relationship points to a corresponding object from another table and a back reference is used the same way, but in the opposite direction.
Venue to address relationship:
Venue(name=’Parish’).address → Address(street=’214 E 6th St’,zip=’78701')
Venue to address back reference:
Address(street=’214 E 6th St’,zip=’78701').venues → Venue(name=’Parish’)
Here is how the venue and address relationship and back reference is implemented in code:
Back to the venue_ratings() function, a back reference is used to get the venue name by calling rated_venue.name. The code for defining rated_venue is in the Venue Mapper class and can be seen below:
Wrap Up
I hope this tutorial has helped you gain a better understanding of Flask and SQLAlchemy. Not all your questions are answered here, and I encourage you to work with the Austin Music Venues app and code to discover the answers on your own. Happy coding!
